
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
前面的一篇文章中,我们学习了 Lucene 的原理和实现机制。并从中了解到 Lucene 提供的全文检索主要用到了,索引的创建和索引的检索。但是 Lucene 中的索引到底存储的是什么呢?为什么它能这么快呢?本文将为你揭开 Lucene 索引的神秘面纱,并讲述反向索引。

索引里面究竟需要存些什么呢?
首先我们来看为什么顺序扫描的速度慢。其实是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
反向索引
反向索引的所保存的信息一般如下:
假设我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构。
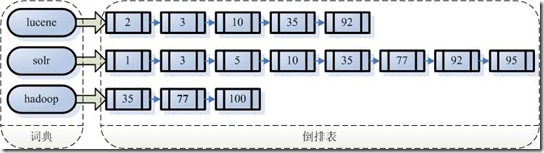
左边保存的是一系列字符串,称为词典 。
每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表 (Posting List)。
有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。
比如说,我们要寻找既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
- 取出包含字符串“lucene”的文档链表。
- 取出包含字符串“solr”的文档链表。
- 通过合并链表,找出既包含“lucene”又包含“solr”的文件。

看到这个地方,有人可能会说,全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。的确,加上索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程。
然而两者还是有区别的,顺序扫描是每次都要扫描,而创建索引的过程仅仅需要一次,以后便是一劳永逸的了,每次搜索,创建索引的过程不必经过,仅仅搜索创建好的索引就可以了。
这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Lucene的索引(Index)里面究竟存些什么?