
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
规则引擎起源于基于规则的专家系统,而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。
利用它就可以在应用系统中分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时可以动态地管理和修改,从而为企业保持灵活性和竞争力提供有效的技术支持。
在需求里面我们往往把约束,完整性,校验,分支流等都可以算到业务规则里面。在规则引擎里面谈的业务规则重点是谈当满足什么样的条件的时候,需要执行什么样的操作。因此一个完整的业务规则包括了条件和触发操作两部分内容。而引擎是事物内部的重要的运行机制,规则引擎即重点是解决规则如何描述,如何执行,如何监控等一系列问题。
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
java开源的规则引擎有:Drools、Easy Rules、Mandarax、IBM ILOG。使用最为广泛并且开源的是Drools。
规则引擎的优点
-
声明式编程
规则可以很容易地解决困难的问题,并得到解决方案的验证。与代码不同,规则以较不复杂的语言编写; 业务分析师可以轻松阅读和验证一套规则。 -
逻辑和数据分离
数据位于“域对象”中,业务逻辑位于“规则”中。根据项目的种类,这种分离是非常有利的。 -
速度和可扩展性
写入Drools的Rete OO算法已经是一个成熟的算法。在Drools的帮助下,您的应用程序变得非常可扩展。如果频繁更改请求,可以添加新规则,而无需修改现有规则。 -
知识集中化
通过使用规则,您创建一个可执行的知识库(知识库)。这是商业政策的一个真理点。理想情况下,规则是可读的,它们也可以用作文档。
rete 算法
Rete 算法最初是由卡内基梅隆大学的 Charles L.Forgy 博士在 1974 年发表的论文中所阐述的算法 , 该算法提供了专家系统的一个高效实现。自 Rete 算法提出以后 , 它就被用到一些大型的规则系统中 , 像 ILog、Jess、JBoss Rules 等都是基于 RETE 算法的规则引擎
Rete 在拉丁语中译为”net”,即网络。Rete 匹配算法是一种进行大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。
其核心思想是将分离的匹配项根据内容动态构造匹配树,以达到显著降低计算量的效果。Rete 算法可以被分为两个部分:规则编译和规则执行。当Rete算法进行事实的断言时,包含三个阶段:匹配、选择和执行,称做 match-select-act cycle。
Rete 算法规则相关的概念有如下几个:
Fact:已经存在的事实,它是指对象之间及对象属性之间的多元关系,为简单起见,事实用一个三元组来表示:(标识符 ^ 属性 值)。
Rule:规则,包含条件和行为两部分,条件部分又叫左手元(LHS),行为部分又叫右手元(RHS)。条件部分可以有多条条件,并且可以用 and 或 or 连接。
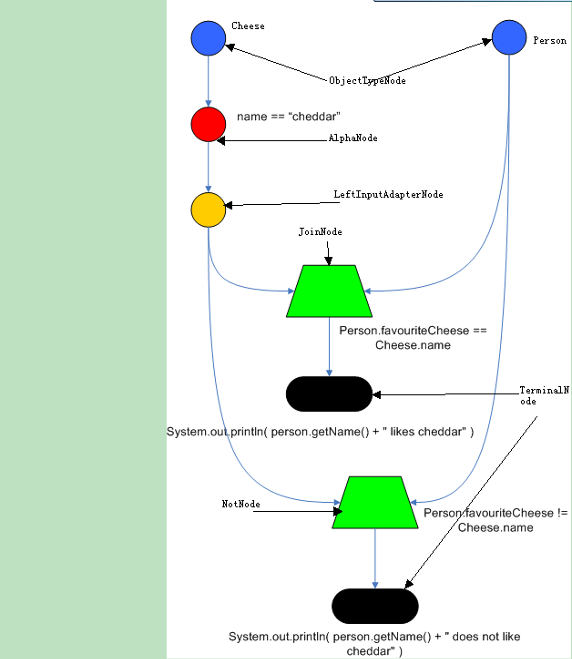
Rete 算法的匹配过程
匹配过程如下:
- 对于每个事实,通过 select 操作进行过滤,使事实沿着 rete 网达到合适的 alpha 节点。
- 对于收到的每一个事实的 alpha 节点,用 Project( 投影操作 ) 将那些适当的变量绑定分离出来。使各个新的变量绑定集沿 rete 网到达适当的 bete 节点。
- 对于收到新的变量绑定的 beta 节点,使用 Project 操作产生新的绑定集,使这些新的变量绑定沿 rete 网络至下一个 beta 节点以至最后的 Project。
- 对于每条规则,用 project 操作将结论实例化所需的绑定分离出来。
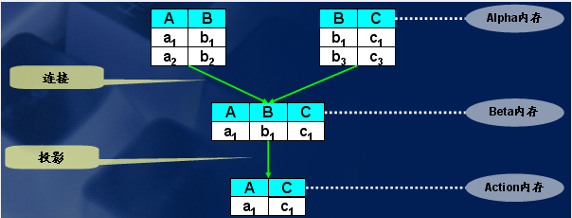
如果把 rete 算法类比到关系型数据库操作,则事实集合就是一个关系,每条规则就是一个查询,再将每个事实绑定到每个模式上的操作看作一个 Select 操作,记一条规则为 P,规则中的模式为 c1,c2,…,ci, Select 操作的结果记为 r(ci), 则规则 P 的匹配即为 r(c1)◇r(c2)◇…◇(rci)。其中◇表示关系的连接(Join)操作。
Rete 网络的连接(Join)和投影 (Project) 和对数据库的操作形象对比如图 3 所示:
Drools 程序
学习一样新东西的最好的方法就是尝试使用它,下面编写一个简单的 Drools 应用程序。首先,我们需要创建一个 Maven 工程,然后在其 pom.xml 文件添加如下包依赖:
<dependencies>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-api</artifactId>
<version>6.5.0.Final</version>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<version>6.5.0.Final</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
在 resources 目录下创建文件 helloworld.drl 文件,内容如下:
package helloworld;
rule "HelloWorld"
when
eval(true)
then
System.out.println("HelloWorld");
end
在 resources/META-INF 目录下创建 kmodule.xml 文件,kmodule.xml 用来描述知识库资源的选择及知识库与会话的配置,内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="helloWorldBase">
<ksession name="helloWorldSession"/>
</kbase>
</kmodule>
创建单元测试类 HelloWorldTest,内容如下:
public class HelloWorldTest {
@Test
public void testHelloWorld() {
KieServices kieServices = KieServices.Factory.get();
KieContainer kieContainer = kieServices.newKieClasspathContainer();
KieSession kieSession = kieContainer.newKieSession("helloWorldSession");
kieSession.fireAllRules();
kieSession.dispose();
}
}
规则语法简介
现在我们已经执行了我们的第一条规则,是时候去了解一下规则语言了。我们先分析下我们之前写的规则,它的结构由条件和结果组成:
package 包名
rule "规则名"
when
(条件) - 也叫作规则的 LHS(Left Hand Side)
then
(动作/结果) - 也叫作规则的 RHS(Right Hand Side)
end
规则引擎虽然非常强大,但并非所有场景都适用。具体可以根据大家的项目来选择吧!

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Drools 项目实战,源码分享