
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
Java 中主要与 hash 有关且常用的4个类:HashMap、HashTable、HashSet、ConcorrentHashMap。本文将介绍它们的一些用法和原理。
HashMap
HashMap是基于hashing的原理,使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当给put()方法传递键和值时,先对键调用 hashCode()方法,返回的hashCode用于找到bucket位置来储存Map.Entry对象。当两个键的hashcode相同,它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。从而解决碰撞问题。或者值时,找到bucket位置之后,会调用keys.equals()方法遍历的找到链表中正确的节点,最终找到要找的值对象。尽量使用不可变的、声明作final的对象,并且采用合适的equals()和 hashCode()方法的话,将会减少碰撞的发生,提高效率。当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放 入新的bucket数组中。这个过程叫作rehashing。在调 整大小的过程中,存储在链表中的元素的次序会反过来,避免尾部遍历。
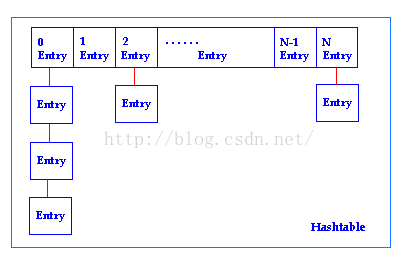
HashMap 原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象 的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的 键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
HashTable
HashTable因为内部是采用synchronized来保证线程安全的,但在线程竞争激烈的情况下HashTable的效率下降得很快因为synchronized关键字会造成代码块或方法成为为临界区(对同一个对象加互斥锁),当一个线程访问临界区的代码时,其他线程也访问同一临界区时,会进入阻塞或轮询状态。
究其原因,实际上是有获取锁意向的线程的数目增加,但是锁还是只有单个,导致大量的线程处于轮询或阻塞,导致同一时间段有效执行的线程的增量远不及线程总体增量。
在查询时,尤其能够体现出CocurrentHashMap在效率上的优势,HashTable使用Sychronized关键字,会导致同时只能有一个查询在执行,而Cocurrent则不采取加锁的方法,而是采用volatile关键字,虽然也会牺牲效率,但是由于Sychronized。
HashMap与HashTable比较
- 二者的存储结构和解决冲突的方法都是相同的。
- HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
- Hashtable中key和value都不允许为null,而HashMap中key和value都允许为null(key只能有一个为null,而value则可以有多个为null)。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
- Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
- Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
HashSet
HashSet是基于HashMap来实现的,操作很简单,更像是对HashMap做了一次“封装”,而且只使用了HashMap的key来实现各种特性。HashSet 不允许有重复元素。
- hashset.add(E e):返回boolean型,如果此 set 中尚未包含指定元素,则添加指定元素;如果此 set 已包含该元素,则该调用不更改 set 并返回 false。
- hashset.clear():从此 set 中移除所有元素。
- hashset.remove(Object o):如果指定元素存在于此 set 中,则将其移除。
- hashset.isEmpty():如果此 set 不包含任何元素,则返回 true。
- hashset.contains(Object o):如果此 set 包含指定元素,则返回 true。
- hashset.size():返回此 set 中的元素的数量(set 的容量)。
ConcorrentHashMap
ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类HashTable的结构,Segment内部维护了一个链表数组,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,ConcurrentHashMap的并发能力可以大大的提高。
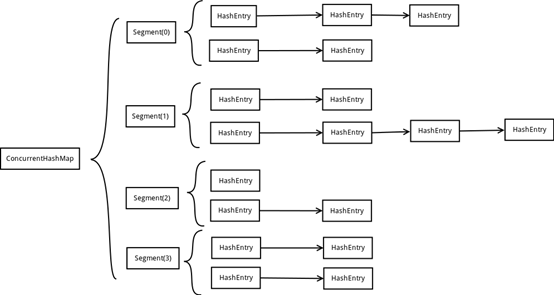
利用锁分段技术增加了锁的数目,从而使争夺同一把锁的线程的数目得到控制。
CurrentHashMap的初始化一共有三个参数,一个initialCapacity,表示初始的容量,一个loadFactor,表示负载参数,最后一个是concurrentLevel,代表ConcurrentHashMap内部的Segment的数量,ConcurrentLevel一经指定,不可改变,后续如果ConcurrentHashMap的元素数量增加导致ConrruentHashMap需要扩容,ConcurrentHashMap不会增加Segment的数量,而只会增加Segment中链表数组的容量大小,这样的好处是扩容过程不需要对整个ConcurrentHashMap做rehash,而只需要对Segment里面的元素做一次rehash就可以了。
锁分段技术
就是对数据集进行分段,每段竞争一把锁,不同数据段的数据不存在锁竞争,从而有效提高高并发访问效率。
CocurrentHashMap在get方法是无需加锁的,因为用到的共享变量都采用volatile关键字修饰,保证共享变量在线程之间的可见性(每次读取都先同步缓存和内存,直接从内存中获取值,虽然不是原子操作,但根据JAVA内存模型的happen before原则,对volatile字段的写入操作先于读操作,能够保证不会脏读),volatile为了让变量提供线程之间的内存可见性,会禁止程序执行结果的重排序(导致缓存优化的效果降低)。
CocurrentHashMap是由Segment数组和HashEntry数组组成。
Segment是重入锁(ReentrantLock),作为一个数据段竞争锁,每个HashEntry一个链表结构的元素,利用Hash算法得到索引确定归属的数据段,也就是对应到在修改时需要竞争获取的锁。
操作
- Segment的get操作是不需要加锁的。因为volatile修饰的变量保证了线程之间的可见性
- Segment的put操作是需要加锁的,在插入时会先判断Segment里的HashEntry数组是否会超过容量(threshold),如果超过需要对数组扩容,翻一倍。然后在新的数组中重新hash,为了高效,CocurrentHashMap只会对需要扩容的单个Segment进行扩容
- CocurrentHashMap获取size的时候要统计Segments中的HashEntry的和,如果不对他们都加锁的话,无法避免数据的修改造成的错误,但是如果都加锁的话,效率又很低。所以CoccurentHashMap在实现的时候,巧妙地利用了在累加过程中发生变化的几率很小的客观条件,在获取count时,不加锁的计算两次,如果两次不相同,在采用加锁的计算方法。采用了一个高效率的剪枝防止很大概率地减少了不必要额加锁。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » java HashMap/HashTable/HashSet/ConcorrentHashMap