
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。这时HTMLParser诞生了。
HTMLParser是一个用来解析HTML文档的开放源码项目,它具有小巧、快速、使用简单的特点以及拥有强大的功能。缺点是相关文档比较少(英文的也少),很多功能需要自己摸索。对于初学者还是要费一些功夫的,而一旦上手以后,会发现HTMLParser的结构设计很巧妙,非常实用,基本你的各种需求都可以满足。另外HTMLParser目前已基本不更新了,它已被jsoup(关于jsoup请阅读:http://www.xttblog.com/?p=326)取代了。
一个HTML文档中可能出现的标签差不多在HTMLParser中都有对应的类,甚至包括一些动态的脚本标签,例如 <%%> 这种JSP和ASP用到的标签都有相应的JspTag对应。HTMLParser的强大功能还体现在你可以修改每个标签的属性或者它所包含的文本内容并生成新的 HTML 文档,比如你可以文档中的链接地址偷偷的改成你自己的地址等等。
HTMLParser的核心模块是org.htmlparser.Parser类,这个类实际完成了对于HTML页面的分析工作。这个类有下面几个构造函数:
public Parser ();
public Parser (Lexer lexer, ParserFeedback fb);
public Parser (URLConnection connection, ParserFeedback fb) throws ParserException;
public Parser (String resource, ParserFeedback feedback) throws ParserException;
public Parser (String resource) throws ParserException;
public Parser (Lexer lexer);
public Parser (URLConnection connection) throws ParserException;
public static Parser createParser (String html, String charset);
使用HtmlPaser的关键步骤:
a.通过Parser类创建一个解释器
b.创建Filter或者Visitor
c.使用parser根据filter或者visitor来取得所有符合条件的节点
d.对节点内容进行处理
HTMLParser将解析过的信息保存为一个树的结构。Node是信息保存的数据类型基础。
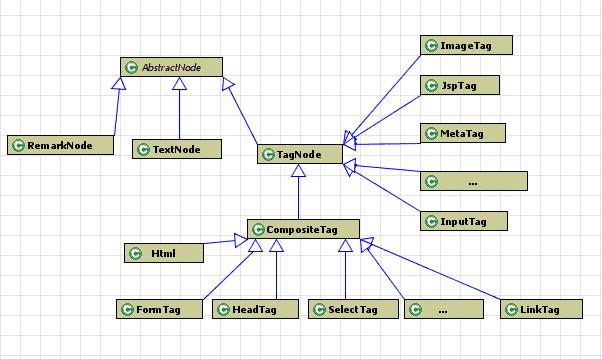
Node中包含的方法有几类:
对于树型结构进行遍历的函数,这些函数最容易理解:
Node getParent ():取得父节点
NodeList getChildren ():取得子节点的列表
Node getFirstChild ():取得第一个子节点
Node getLastChild ():取得最后一个子节点
Node getPreviousSibling ():取得前一个兄弟(不好意思,英文是兄弟姐妹,直译太麻烦而且不符合习惯,对不起女同胞了)
Node getNextSibling ():取得下一个兄弟节点
取得Node内容的函数:
String getText ():取得文本
String toPlainTextString():取得纯文本信息。
String toHtml () :取得HTML信息(原始HTML)
String toHtml (boolean verbatim):取得HTML信息(原始HTML)
String toString ():取得字符串信息(原始HTML)
Page getPage ():取得这个Node对应的Page对象
int getStartPosition ():取得这个Node在HTML页面中的起始位置
int getEndPosition ():取得这个Node在HTML页面中的结束位置
用于Filter过滤的函数:
void collectInto (NodeList list, NodeFilter filter):基于filter的条件对于这个节点进行过滤,符合条件的节点放到list中。
用于Visitor遍历的函数:
void accept (NodeVisitor visitor):对这个Node应用visitor
用于修改内容的函数,这类用得比较少:
void setPage (Page page):设置这个Node对应的Page对象
void setText (String text):设置文本
void setChildren (NodeList children):设置子节点列表
其他函数:
void doSemanticAction ():执行这个Node对应的操作(只有少数Tag有对应的操作)
Object clone ():接口Clone的抽象函数。
下面是一个解析指定节点的例子,html内容:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>HTMLParser解析——业余草</title>
<style type="text/css">
body{
background: #f5faff;
}
</style>
</head>
<body>
<div class="xttblog">
<div class="yeyucao"></div>
</div>
<script type="text/javascript">
alert('ss');
</script>
</body>
</html>
java解析代码:
package test;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.Tag;
import org.htmlparser.util.NodeList;
/**
* HTMLParser解析html
* @author Herman.Xiong
* @date 2016年3月31日13:49:27
*/
public class HTMLParserTest {
public static void main(String[] args) {
//解析指定节点的例子
try{
Parser parser = new Parser("http://127.0.0.1:8080/h5site/6.html");
parser.setEncoding("GBK");
NodeList nodeList = parser.extractAllNodesThatMatch(new NodeFilter() {
private static final long serialVersionUID = 1L;
public boolean accept(Node node) {
return ((node instanceof Tag)
&& !((Tag)node).isEndTag()
&& ((Tag)node).getTagName().equals("DIV")
&& ((Tag)node).getAttribute("class") != null
&& ((Tag)node).getAttribute("class").equals("xttblog"));
}
});
Node node = nodeList.elementAt(0);
System.out.println(node.toHtml());
} catch( Exception e ) {
e.printStackTrace();
}
}
}
原文地址:http://www.xttblog.com/?p=322

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » 爬虫解析网页内容HTMLParser使用详解