
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
Field 有人称之为字段,也有人称之为域,看个人爱好。在 Lucene 中,Field 域非常的重要。一个文档 Document 可以包括多个 Field,Document 只是 Field 的一个承载体,Field 值即为要索引的内容,也是要搜索的内容。所以,我们很有必要系统的学习一下 Field 域!
一个 Field 域决定了是否分词(tokenized)、是否索引(indexed)、是否存储(stored)。
- 分词 tokenized:分词是靠分词器 Analyzer,前面有介绍过。分词也就是一个 token 化的过程。一般将 Field 值进行分词,分词的目的是为了索引。
- 索引 indexed:将 Field 分词后的词或整个 Field 值进行索引,索引的目的是为了搜索。
- 存储 stored:将 Field 值存储在文档中,存储在文档中的 Field才 可以从 Document 中获取。
下面以图书为例,看几个 Field 域的分词场景。
图书id:
是否分词:不用分词,因为不会根据商品id来搜索商品
是否索引:不索引,因为不需要根据图书ID进行搜索
是否存储:要存储,因为查询结果页面需要使用id这个值。图书名称:
是否分词:要分词,因为要将图书的名称内容分词索引,根据关键搜索图书名称抽取的词。
是否索引:要索引。
是否存储:要存储。图书价格:
是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词和索引,因为lucene对数字型的内容要特殊分词处理,本例子可能要根据价格范围搜索,需要分词和索引。
是否索引:要索引
是否存储:要存储图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。不存储是指不在 lucene 的索引文件中记录,节省 lucene 的索引文件空间,如果要在详情页面显示描述,可以从 lucene 中取出图书的 id,根据图书的 id 查询关系数据库中 book 表得到描述信息。
以前面的创建索引为例,我们来看看 Field 域的使用。
@Test
public void createIndex() throws Exception {
// 采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks();
// 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
// 不分词、索引、存储 StringField
Field id = new StringField("id", book.getId().toString(), Store.YES);
// 图书名称
// 分词、索引、存储 TextField
Field name = new TextField("name", book.getName(), Store.YES);
// 图书价格
// 分词、索引、存储 但是是数字类型,所以使用FloatField
Field price = new FloatField("price", book.getPrice(), Store.YES);
// 图书图片地址
// 不分词、不索引、存储 StoredField
Field pic = new StoredField("pic", book.getPic());
// 图书描述
// 分词、索引、不存储 TextField
Field description = new TextField("description",
book.getDescription(), Store.NO);
// 设置boost值
if (book.getId() == 4)
description.setBoost(100f);
// 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description);
docList.add(document);
}
}
下面对上面使用的几个 Field 做一下简单的解释。
- TextField:是一个会自动被索引和分词的字段。一般被用在文章的正文部分
- StringField:StringField 会被索引,但是不会被分词,即会被当作一个完整的 token 处理,一般用在“国家”或者“ID”
- StoredField:也就是一个默认会被存储的 Field
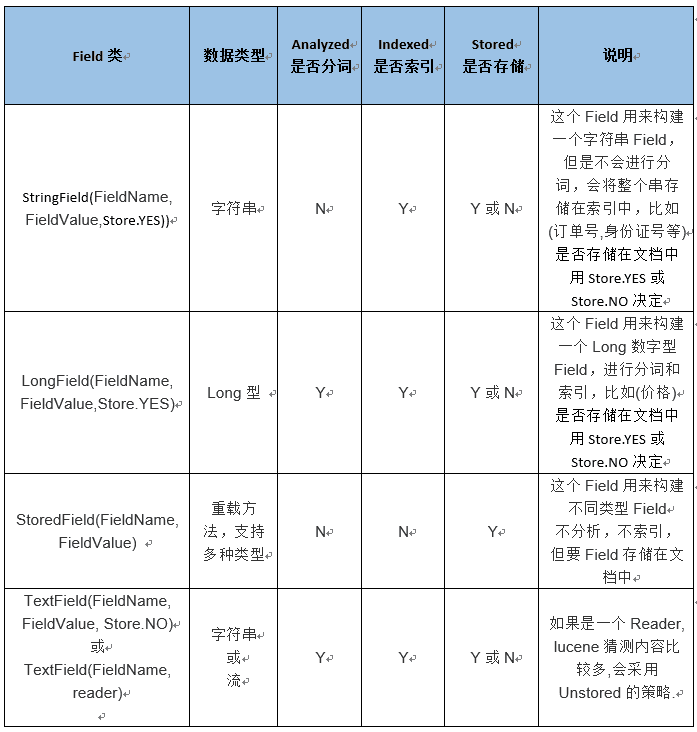
IndexableField 接口
在 Lucene 中,各种 Field 都是 IndexableField 接口的实现,该接口中提供了一些通用的方法,用于获取 Field 相关的属性。
public interface IndexableField {
//获取名称
public String name();
//获取Field的类型
public IndexableFieldType fieldType();
//获取Field的权重
public float boost();
/** Non-null if this field has a binary value */
public BytesRef binaryValue();
/** Non-null if this field has a string value */
public String stringValue();
/** Non-null if this field has a Reader value */
public Reader readerValue();
/** Non-null if this field has a numeric value */
public Number numericValue();
}
注意上面的 fieldType() 方法,一般通过该方法获取到该 Field 对应的 FieldType 类型,但是却并不能去调用 FieldType 一系列的 set 方法。如果通过 fieldType().setStored(true); 进行 set 操作,则会报 java.lang.IllegalStateException: this FieldType is already frozen and cannot be changed。这是因为各 Field 的子类中,都调用了 type.freeze() 方法,而该方法就可以阻止对 fieldType 做更改。
更多 Field 见下表,注意有些 Field 在一些老版本中是使用 Point 来表示的。FloatField 等价于 FloatPoint,LongField 等价于 LongPoint,DoubleField 等价于 为DoublePoint。
| 名称 | 说明 |
|---|---|
| IntPoint | 对int型字段索引,只索引不存储,提供了一些静态工厂方法用于创建一般的查询,提供了不同于文本的数值类型存储方式,使用KD-trees索引 |
| FloatPoint | 对float型字段索引,其它同上 |
| LongPoint | 对long型字段索引,其它同上 |
| DoublePoint | 对double型字段索引,其它同上 |
| BinaryDocValuesField | 只存储不共享,例如标题类字段,如果需要共享并排序,推荐使用SortedDocValuesField |
| NumericDocValuesField | 存储long型字段,用于评分、排序和值检索,如果需要存储值,还需要添加一个单独的StoredField实例 |
| SortedDocValuesField | 索引并存储,用于String类型的Field排序,需要在StringField后添加同名的SortedDocValuesField |
| StringField | 只索引但不分词,所有的字符串会作为一个整体进行索引,例如通常用于country或id等 |
| TextField | 索引并分词,不包括term vectors,例如通常用于一个body Field |
| StoredField | 存储Field的值,可以用 IndexSearcher.doc和IndexReader.document来获取存储的Field和存储的值 |
好了,今天关于 Field 的介绍就先到这里,下章我们继续。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!