
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
基于我们的数据特性,在进行数据库选型时选择了 mongo 数据库。在文档数量很大的情况下,存在慢查询,影响服务端性能。合理地对数据库命令及索引进行优化,可以很大幅度提升接口性能。
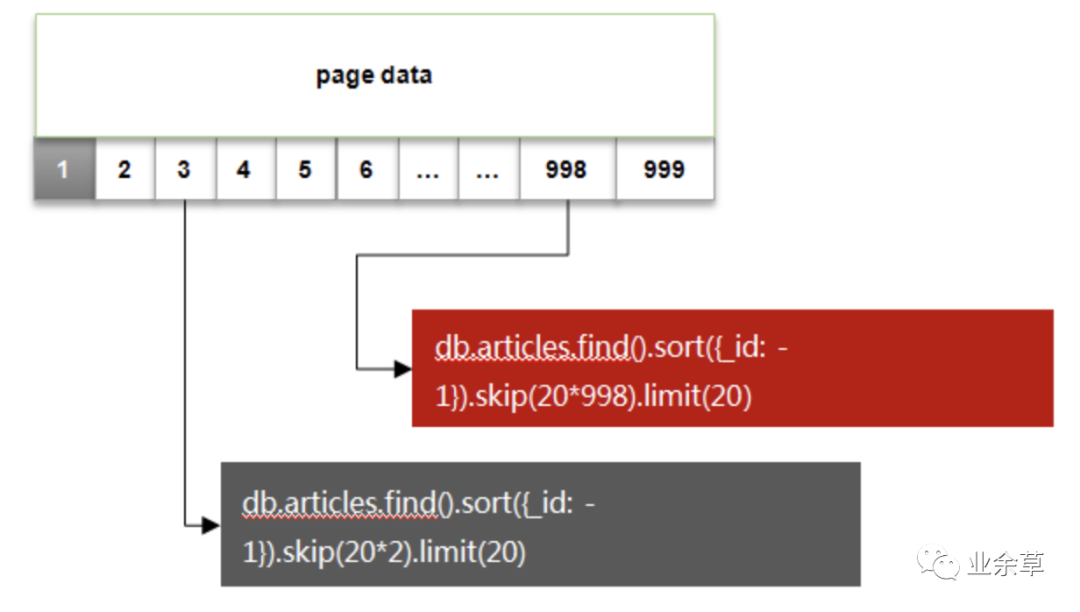
mongo 分页查询
在 Java 中使用 mongodb 的 MongoTemplate 进行分页时,一般的策略是使用 skip+limit 的方式,但是这种方式在需要略过大量数据的时候就显得很低效。
传统分页介绍
假设一页大小为 10 条。则:
//page 1
1-10
//page 2
11-20
//page 3
21-30
...
//page n
10*(n-1)+1-10*nMongoDB 提供了 skip() 和 limit() 方法。
skip: 跳过指定数量的数据。可以用来跳过当前页之前的数据,即跳过 pageSize*(n-1)。limit: 指定从 MongoDB 中读取的记录条数,可以当做页面大小 pageSize。
所以,分页可以这样做:
//Page 1
db.getCollection('file').find({}).limit(10)
//Page 2
db.getCollection('file').find({}).skip(10).limit(10)
//Page 3
db.getCollection('file').find({}).skip(20).limit(10)
........存在问题
官方文档对 skip 的描述:
skip 方法从结果集的开头进行扫描后返回查询结果。这样随着偏移的增加,skip 将变得更慢。
❝
The cursor.skip() method requires the server to scan from the beginning of the input results set before beginning to return results. As the offset increases, cursor.skip() will become slower.❞
所以,需要一种更快的方式。其实和 mysql 数量大之后不推荐用 limit m,n 一样。
官方建议使用范围查询,可以使用[索引]分页相比,偏移量增加时通常会产生更好的性能。即指定开始位置解决方案是先查出当前页的第一条,然后顺序数 pageSize 条。
指定范围分页介绍
我们假设基于_id的条件进行查询比较。事实上,这个比较的基准字段可以是任何你想要的有序的字段,比如时间戳。
//Page 1
db.getCollection('file').find({}).limit(pageSize);
//Find the id of the last document in this page
last_id =...
//Page 2
users =db.getCollection('file').find({
'_id':{"$gt":ObjectId("5b16c194666cd10add402c87")}
}).limit(10)
//Update the last id with the id of the last document in this page
last_id =...显然,第一页和后面的不同。对于构建分页 API,我们可以要求用户必须传递 pageSize,lastId。
「pageSize」 页面大小
「lastId」 上一页的最后一条记录的 id,如果不传,则将强制为第一页。
降序
_id降序,第一页是最大的,下一页的 id 比上一页的最后的 id 还小。
db.getCollection('file').find({ _id:{ $lt:lastId}})
.sort({ _id:-1})
.limit(pageSize)升序
_id升序,下一页的 id 比上一页的最后一条记录 id 还大。
db.getCollection('file').find({ _id:{ $gt:lastId}})
.sort({ _id:1})
.limit(pageSize )总条数
还有一共多少条和多少页的问题。所以,需要先查一共多少条 count。
db.getCollection('file').find({}).count();ObjectId 的有序性问题。
先看 ObjectId 生成规则:
比如"_id" : ObjectId("5b1886f8965c44c78540a4fc")。
取 id 的前 4 个字节。由于 id 是 16 进制的 string,4 个字节就是 32 位,对应 id 前 8 个字符。即 5b1886f8, 转换成 10 进制为 1528334072. 加上 1970,就是当前时间。
事实上,更简单的办法是查看 org.mongodb:bson:3.4.3 里的 ObjectId 对象。
publicObjectId(Date date){
this(dateToTimestampSeconds(date), MACHINE_IDENTIFIER, PROCESS_IDENTIFIER, NEXT_COUNTER.getAndIncrement(),false);
}
//org.bson.types.ObjectId#dateToTimestampSeconds
privatestatic int dateToTimestampSeconds(Date time){
return(int)(time.getTime()/ 1000L);
}
//java.util.Date#getTime
/**
* Returns the number of milliseconds since January 1, 1970, 00:00:00 GMT
* represented by this <tt>Date</tt> object.
*
* @return the number of milliseconds since January 1, 1970, 00:00:00 GMT
* represented by this date.
*/
public long getTime(){
returngetTimeImpl();
}MongoDB 的 ObjectId 应该是随着时间而增加的,即后插入的 id 会比之前的大。但考量 id 的生成规则,最小时间排序区分是秒,同一秒内的排序无法保证。当然,如果是同一台机器的同一个进程生成的对象,是有序的。
如果是分布式机器,不同机器时钟同步和偏移的问题。所以,如果你有个字段可以保证是有序的,那么用这个字段来排序是最好的。_id则是最后的备选方案。
存在问题
上面的分页看起来看理想,虽然确实是,但有个问题是不能无法做到跳页。
我们的分页数据要和排序键关联,所以必须有一个排序基准来截断记录。而跳页,我只知道第几页,条件不足,无法分页了。
现实业务需求确实提出了跳页的需求,虽然几乎不会有人用,人们更关心的是开头和结尾,而结尾可以通过逆排序的方案转成开头。所以,真正分页的需求应当是不存在的。如果你是为了查找某个记录,那么查询条件搜索是最快的方案。如果你不知道查询条件,通过肉眼去一一查看,那么下一页足矣。
说了这么多,就是想扭转传统分页的概念,在互联网发展的今天,大部分数据的体量都是庞大的,跳页的需求将消耗更多的内存和 cpu,对应的就是查询慢。
当然,如果数量不大,如果不介意慢一点,那么 skip 也不是啥问题,关键要看业务场景。
我今天接到的需求就是要跳页,而且数量很小,那么 skip 吧,不费事,还快。
比如 google,看起来是有跳页选择的啊。再仔细看,只有 10 页,多的就必须下一页,并没有提供一共多少页,跳到任意页的选择。这不就是我们的 find-condition-then-limit 方案吗,只是他的一页数量比较多,前端或者后端把这一页给切成了 10 份。

同样,Facebook,虽然提供了总 count,但也只能下一页。

其他场景,比如 Twitter,微博,朋友圈等,根本没有跳页的概念的。
如果确实有跳页的需求,可以仍旧采用 skip 做分页,目前还没有发现性能问题。
private List<DBObject> doFindItems(String collectionName,
Map<String, Object> query, DBObject showFields, int skip,
int limit, DBObject order) {
List<DBObject> result = null;
DBObject obj = genDBObject(query);
DBCursor cursor = readDB.getCollection(collectionName)
.find(obj, showFields);
if (cursor != null) {
try {
if (order != null) {
cursor.sort(order);
}
cursor.skip(skip).limit(limit);
result = cursor.toArray();
} finally {
cursor.close();
}
}
return result;
}排序和性能
前面关注于分页的实现原理,但忽略了排序。既然分页,肯定是按照某个顺序进行分页的,所以必须要有排序的。
MongoDB 的 sort 和 find 组合
db.getCollection('file').find().sort({'createTime':1}).limit(5)
db.getCollection('file').find().limit(5).sort({'createTime':1})这两个都是等价的,顺序不影响执行顺序。即,都是先 find 查询符合条件的结果,然后在结果集中排序。
我们条件查询有时候也会按照某字段排序的,比如按照时间排序。查询一组时间序列的数据,我们想要按照时间先后顺序来显示内容,则必须先按照时间字段排序,然后再按照 id 升序。
db.getCollection('file').find({productId:5}).sort({createTime:1, _id:1}).limit(5)我们先按照 createTime 升序,然后 createTime 相同的 record 再按照_id 升序,如此可以实现我们的分页功能了。
多字段排序
db.getCollection('file').sort({taskRole:1,appId:-1})表示先按照 taskRole 升序,再按 appId 降序。
示例:
db.getCollection('file').find({});
/* 结果:*/
/* 1 */
{
"_id" : ObjectId("5e7179de0af8595d0bbe243f"),
"fileName" : "test.apk",
"fileCTime" : NumberLong(1584495748123),
"version" : "1"
}
/* 2 */
{
"_id" : ObjectId("5e7dc423e20bc4b7fa6c205a"),
"fileName" : "b.html",
"version" : "2"
}
/* 3 */
{
"_id" : ObjectId("5e7dc423e20bc4b7fa6c205b"),
"fileName" : "b.html",
"version" : "3"
}按照 fileName 升序,然后按照 version 降序。
db.getCollection('file').find({}).sort({fileName:1,version:-1})
/*结果:*/
/* 1 */
{
"_id" : ObjectId("5e7dc423e20bc4b7fa6c205a"),
"fileName" : "b.html",
"version" : "2 "
}
/* 2 */
{
"_id" : ObjectId("5e7dc423e20bc4b7fa6c205b"),
"fileName" : " b.html",
"version" : "3"
}
/* 3 */
{
"_id" : ObjectId("5e7179de0af8595d0bbe243f"),
"fileName" : "test.apk",
"fileCTime" : NumberLong(1584495748123),
"version" : "1"
}以上内容希望能对大家有所帮助!

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Mongodb 的海量数据分页查询优化实战!